

Definition
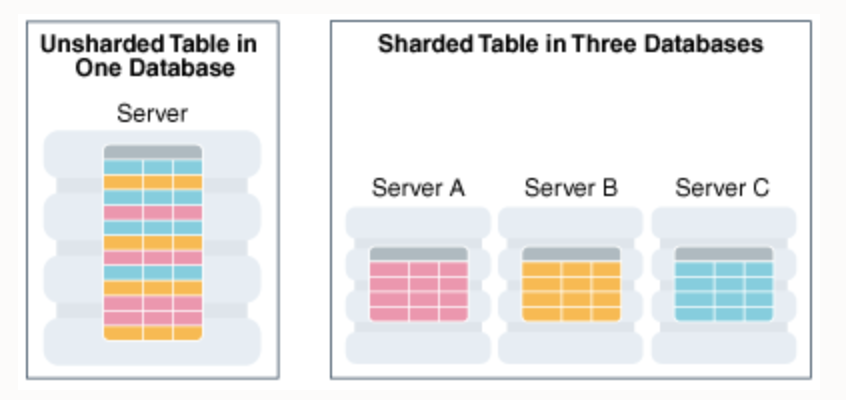
A database shard, or simply a shard, is a horizontal partition of data in a database or search engine. Each shard is held on a separate database server instance, to spread load.
Horizontal partitioning is a database design principle whereby rows of a database table are held separately, rather than being split into columns (which is what normalization and vertical partitioning do, to differing extents). Each partition forms part of a shard, which may in turn be located on a separate database server or physical location.
Some data within a database remains present in all shards but some appears only in a single shard. Each shard (or server) acts as the single source for this subset of data
Some data within a database remains present in all shards but some appears only in a single shard. Each shard (or server) acts as the single source for this subset of data
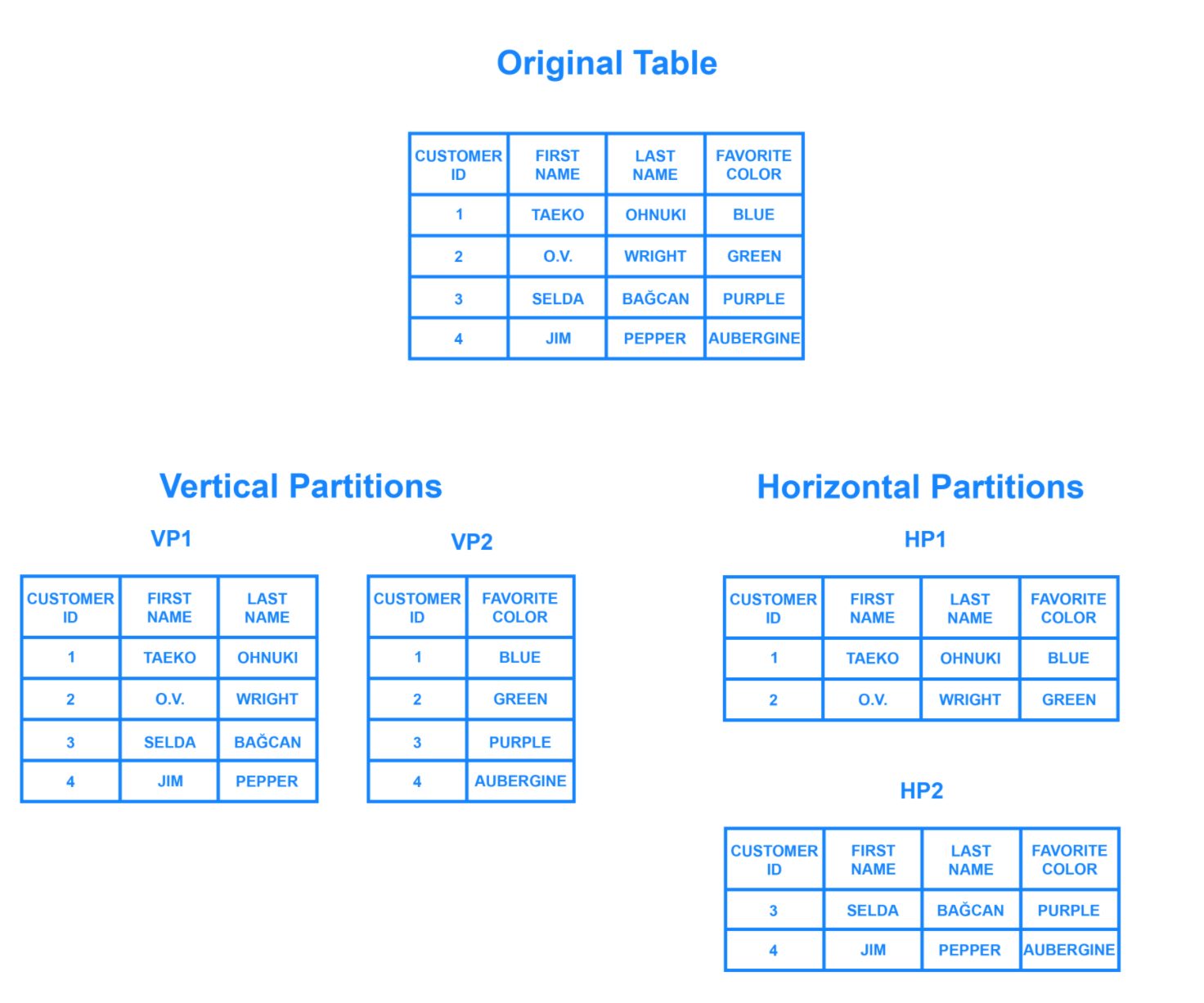
Sharding involves breaking up one’s data into two or more smaller chunks, called logical shards. The logical shards are then distributed across separate database nodes, referred to as physical shards, which can hold multiple logical shards. Despite this, the data held within all the shards collectively represent an entire logical dataset.
Database shards exemplify a shared-nothing architecture. This means that the shards are autonomous; they don’t share any of the same data or computing resources. In some cases, though, it may make sense to replicate certain tables into each shard to serve as reference tables.
Oftentimes, sharding is implemented at the application level, meaning that the application includes code that defines which shard to transmit reads and writes to. However, some database management systems have sharding capabilities built in, allowing you to implement sharding directly at the database level.
Shards compared to horizontal partitioning
Horizontal partitioning splits one or more tables by row, usually within a single instance of a schema and a database server. It may offer an advantage by reducing index size (and thus search effort) provided that there is some obvious, robust, implicit way to identify in which partition a particular row will be found, without first needing to search the index, e.g., the classic example of the ‘CustomersEast‘ and ‘CustomersWest‘ tables, where their zip code already indicates where they will be found.
Sharding goes beyond this: it partitions the problematic table(s) in the same way, but it does this across potentially multiple instances of the schema. The obvious advantage would be that search load for the large partitioned table can now be split across multiple servers (logical or physical), not just multiple indexes on the same logical server.
Splitting shards across multiple isolated instances requires more than simple horizontal partitioning. The hoped-for gains in efficiency would be lost, if querying the database required multiple instances to be queried, just to retrieve a simple dimension table. Beyond partitioning, sharding thus splits large partitionable tables across the servers, while smaller tables are replicated as complete units.[clarification needed]
This is also why sharding is related to a shared-nothing architecture—once sharded, each shard can live in a totally separate logical schema instance / physical database server / data center / continent. There is no ongoing need to retain shared access (from between shards) to the other unpartitioned tables in other shards.
This makes replication across multiple servers easy (simple horizontal partitioning does not). It is also useful for worldwide distribution of applications, where communications links between data centers would otherwise be a bottleneck.
There is also a requirement for some notification and replication mechanisms between schema instances, so that the unpartitioned tables remain as closely synchronized as the application demands. This is a complex choice in the architecture of sharded systems: approaches range from making these effectively read-only (updates are rare and batched), to dynamically replicated tables (at the cost of reducing some of the distribution benefits of sharding) and many options in between.
Architecture
In this section, we’ll go over a few common sharding architectures, each of which uses a slightly different process to distribute data across shards
Key Based Sharding
Key based sharding, also known as hash based sharding, involves using a value taken from newly written data — such as a customer’s ID number, a client application’s IP address, a ZIP code, etc. — and plugging it into a hash function to determine which shard the data should go to.
A hash function is a function that takes as input a piece of data (for example, a customer email) and outputs a discrete value, known as a hash value. In the case of sharding, the hash value is a shard ID used to determine which shard the incoming data will be stored on.
Altogether, the process looks like this:
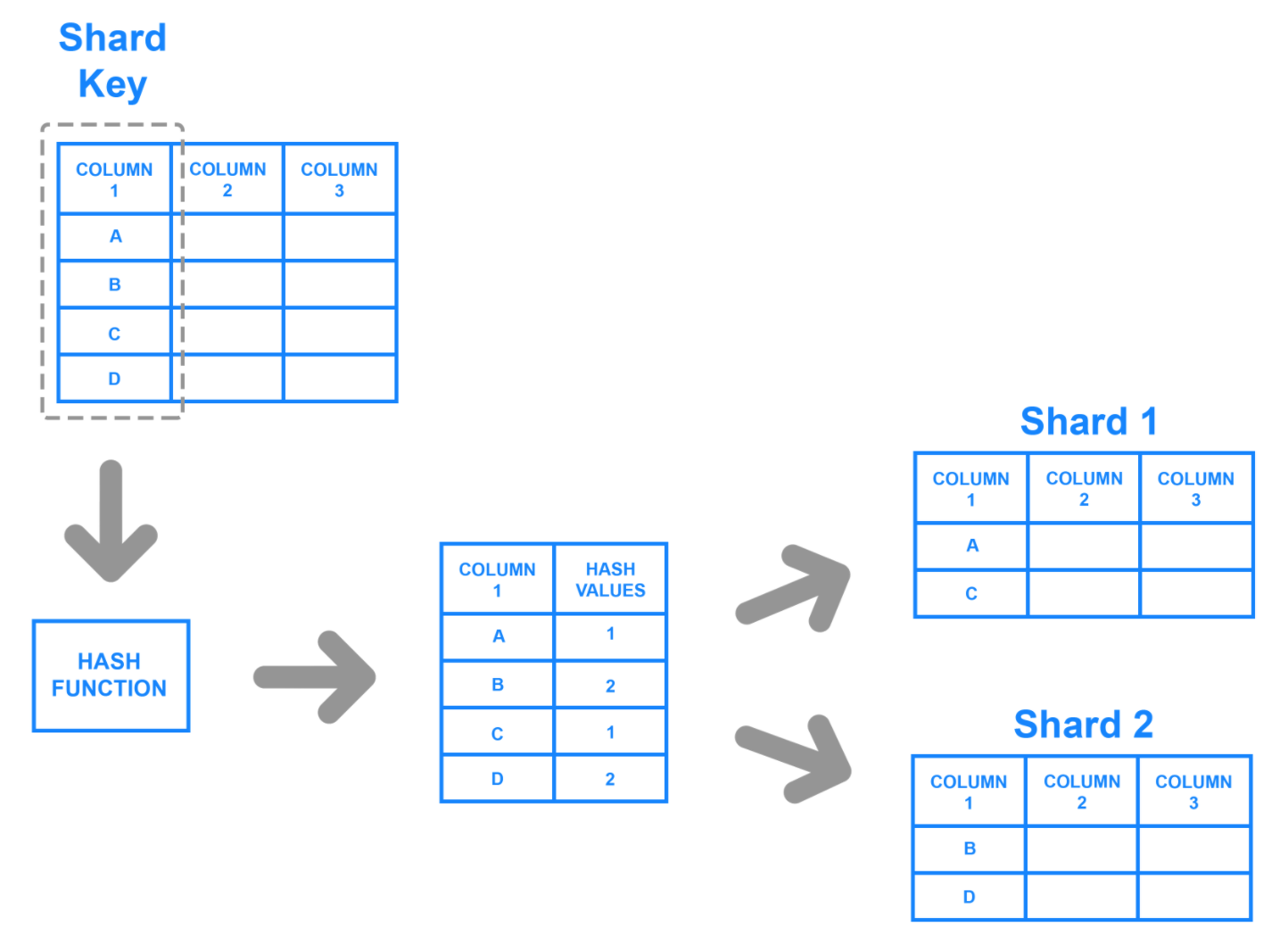
To ensure that entries are placed in the correct shards and in a consistent manner, the values entered into the hash function should all come from the same column.
This column is known as a shard key. In simple terms, shard keys are similar to primary keys in that both are columns which are used to establish a unique identifier for individual rows.
Broadly speaking, a shard key should be static, meaning it shouldn’t contain values that might change over time. Otherwise, it would increase the amount of work that goes into update operations, and could slow down performance.
While key based sharding is a fairly common sharding architecture, it can make things tricky when trying to dynamically add or remove additional servers to a database. As you add servers, each one will need a corresponding hash value and many of your existing entries, if not all of them, will need to be remapped to their new, correct hash value and then migrated to the appropriate server. As you begin rebalancing the data, neither the new nor the old hashing functions will be valid. Consequently, your server won’t be able to write any new data during the migration and your application could be subject to downtime.
The main appeal of this strategy is that it can be used to evenly distribute data so as to prevent hotspots. Also, because it distributes data algorithmically, there’s no need to maintain a map of where all the data is located, as is necessary with other strategies like range or directory based sharding.
Range Based Sharding
Range based sharding involves sharding data based on ranges of a given value.

The main benefit of range based sharding is that it’s relatively simple to implement. Every shard holds a different set of data but they all have an identical schema as one another, as well as the original database. The application code just reads which range the data falls into and writes it to the corresponding shard.
On the other hand, range based sharding doesn’t protect data from being unevenly distributed, leading to the aforementioned database hotspots. Looking at the example diagram, even if each shard holds an equal amount of data the odds are that specific products will receive more attention than others. Their respective shards will, in turn, receive a disproportionate number of reads.
Directory Based Sharding
To implement directory based sharding, one must create and maintain a lookup table that uses a shard key to keep track of which shard holds which data. In a nutshell, a lookup table is a table that holds a static set of information about where specific data can be found.

Directory based sharding is a good choice over range based sharding in cases where the shard key has a low cardinality and it doesn’t make sense for a shard to store a range of keys. Note that it’s also distinct from key based sharding in that it doesn’t process the shard key through a hash function; it just checks the key against a lookup table to see where the data needs to be written.
The main appeal of directory based sharding is its flexibility. Directory based sharding, on the other hand, allows you to use whatever system or algorithm you want to assign data entries to shards, and it’s relatively easy to dynamically add shards using this approach.
While directory based sharding is the most flexible of the sharding methods discussed here, the need to connect to the lookup table before every query or write can have a detrimental impact on an application’s performance. Furthermore, the lookup table can become a single point of failure: if it becomes corrupted or otherwise fails, it can impact one’s ability to write new data or access their existing data.
Disadvatages
- SQL complexity – Increased bugs because the developers have to write more complicated SQL to handle sharding logic
- Additional software – that partitions, balances, coordinates, and ensures integrity can fail
- Single point of failure – Corruption of one shard due to network/hardware/systems problems causes failure of the entire table.
- Fail-over server complexity – Fail-over servers must have copies of the fleets of database shards.
- Backups complexity – Database backups of the individual shards must be coordinated with the backups of the other shards.
- Operational complexity – Adding/removing indexes, adding/deleting columns, modifying the schema becomes much more difficult.
Notable implementations
- Altibase provides combined (client-side and server-side) sharding architecture transparent to client applications.
- Apache HBase can shard automatically.
- Azure SQL Database Elastic Database tools shards to scale out and in the data-tier of an application.
- Couchbase shards automatically and transparently.
- CUBRID shards since version 9.0
- DRDS (Distributed Relational Database Service) of Alibaba Cloud does database/table sharding, and supports Singles’ Day.
- Elasticsearch enterprise search server shards.
- eXtreme Scale is a cross-process in-memory key/value data store (a NoSQL data store). It uses sharding to achieve scalability across processes for both data and MapReduce style parallel processing.
- Hibernate shards, but has had little development since 2007.
- IBM Informix shards since version 12.1 xC1 as part of the MACH11 technology. Informix 12.10 xC2 added full compatibility with MongoDB drivers, allowing the mix of regular relational tables with NoSQL collections, while still allowing sharding, fail-over and ACID properties.
- Kdb+ shards since version 2.0.
- MonetDB, an open-source column-store, does read-only sharding in its July 2015 release.
- MongoDB shards since version 1.6.
- MySQL Cluster automatically and transparently shards across low-cost commodity nodes, allowing scale-out of read and write queries, without requiring changes to the application.
- MySQL Fabric (part of MySQL utilities) shards.
- Oracle Database shards since 12c Release 2 and in one liner: Combination of sharding advantages with well-known capabilities of enterprise ready multi-model Oracle Database.
- Oracle NoSQL Database has automatic sharding and elastic, online expansion of the cluster (adding more shards).
- OrientDB shards since version 1.7
- Solr enterprise search server shards.
- Spanner, Google’s global-scale distributed database, shards across multiple Paxos state machines to scale to “millions of machines across hundreds of data centers and trillions of database rows”.
- SQLAlchemy ORM, a data-mapper for the Python programming language shards.
- The DWH of Teradata: a massive parallel database.
- Vault, a cryptocurrency, shards to drastically reduce the data that users need to join the network and verify transactions. This allows the network to scale much more.
- Vitess open-source database clustering system shards MySQL. It is a Cloud Native Computing Foundation project.
- ShardingSphere related to a database clustering system providing data sharding, distributed transactions, and distributed database management . It is a Apache Software Foundation (ASF) project.
To learn more about system architecture, database and system design, check out out blogs

Leave a Reply